目录 |
工作中的一天下午,大概是16点左右。我旁边的一位爷生气的看着我,让我莫名的有种压力。我心头一紧赶紧追问怎么回事?这位爷气冲冲的告诉我他在解决一个问题,在解决问题的过程中让需求方硬生生的给秀逗了。爷告诉我这都高级工程师了竟然会不知道中文编码的占位问题,关键是这位还竟然在群里众目睽睽地说爷的不是。所以,这位爷找不到撒气的对象了,我心想得我也别招惹这位爷的注意力赶紧结束话题干自己的事情。结果没想到,这位爷还兴冲冲的要问我几个问题。我也不知道哪来的勇气满口答应,让他放马过来。结果我也彻彻底底的秀了一次智商下限。问我的问题让我这位职场老鸟受到了奇耻大辱。所以,我当即下定了决心得恶补一下关于字符集的知识。所以,我才过来写这篇总结。
因为字符集类问题是很庞大的,所以让我们来规定几种字符集先。让我就unicode,gbk,ascii等字符集先做一定的温习。
首先,我们来说说我们比较常用的编码之间的关系,好来展开这篇文章的复习。当计算机问世的时候因为是美国人造的,所以美国人就用了些英文字母和标点符号和辅助型符号,这些字符加起来也不过128位,所以就诞生了ASCII码。后来发展到了欧洲,欧洲那么多国家,每个国家的字母都不太一样,所以人们就扩充了字符集,从而出了拉丁语系的ISO8859-1字符集。再后来中国人参与进来了,我们中国字常用就7000多个。以现有的字符集根本承载不下来那么多字体,那人们就创造出来了GBK字符集,这种字符集和之前两种的区别就是GBK使用两个字节来存储的,其中收录了21003个字符。再后来又出了GB18030,可以收录数量达到了70244个。这个编码采用了1,2,4字节的存储方式,具体存储方式先不说。这个时候人们发现随着用来存储的字节的增多,存储量也变的巨大了。所以,传输的过程中效率问题捉襟见肘。于是,人们就开始考虑更好的存储方法,既能够囊括更多的字符同时存储的容量又不会急剧的膨胀。那么就需要一种智慧的存储方案来解决,于是unicode编码营运而生。unicode编码采用变长的存储结构,通过高位的特殊位数来规定采用的字节数,从而达到了目的。unicode中分为三类:utf8,utf16和utf32。主要用的还是utf8,而且utf8已然成为现如今世界上最为普遍的编码。
一、ASCII码
我们知道,计算机内部存储的数据都是二进制值。每一个二进制位(bit)有0和1两种状态。因此,八个二进制可以组合出256种状态,由八位组成一个字节,即从00000000到11111111。下表是128种ascii码表。当时规定最高位为0,剩下的七位来分别表示这128个字符。

二、非ASCII码
可是,当高1位为1的时候,还没有利用上。所以,有的国家就开辟了剩下的128个字符,但是随之而来的问题也接踵而来。问题是每个国家都可以扩充这后128位,最终导致前一128个都是相同的,但是后128个就不同国家都不一样了。如果再这么继续下去整个世界对于字符上就不再统一了,这简直就是个噩梦。于是,美国人开发出了unicode编码。

三、Unicode码
Unicode是一本很厚的字典,记录着世界上所有字符对应的一个数字。我们可以通过这两个网站查看到每个字符相对应的存储数值,unicode.org和unicode对照表
四、UTF-8
unicode主要遇到了两个问题:
- 如何让计算机区分出来
- 如何使存储空间更小
UTF-8是目前互联网上使用最广泛的一种unicode编码方式了,它主要的特点就是变长。它可以使用1-4个字符表示一个字符(零几年还有6个字符表示的方法,但是后来取消掉了)。规则如下:
- 对于单个字节的字符,第一位设为 0,后面的 7 位对应这个字符的 Unicode 码点。因此,对于英文中的 0 - 127 号字符,与 ASCII 码完全相同。这意味着 ASCII 码那个年代的文档用 UTF-8 编码打开完全没有问题。
- 对于需要使用 N 个字节来表示的字符(N > 1),第一个字节的前 N 位都设为 1,第 N + 1 位设为0,剩余的 N - 1 个字节的前两位都设位 10,剩下的二进制位则使用这个字符的 Unicode 码点来填充。
| Unicode 十六进制码点范围 | UTF-8 二进制 |
|---|---|
| 0000 0000 - 0000 007F | 0xxxxxxx |
| 0000 0080 - 0000 07FF | 110xxxxx 10xxxxxx |
| 0000 0800 - 0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 0001 0000 - 0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
下面,我们用帆字为例进行讲解
帆的unicode十六进制是5E06,补全后位0000 5E06,二进制是0101 1110 0000 0110。跟具上表可以得知是在第三列范围内的。所以帆的utf8编码需要三个字节,即格式为1110xxxx 10xxxxxx 10xxxxxx。从最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0,就得到了11100101 10111000 10000110,转换成十六进制后得到utf8十六进制E5 B8 86。我们可以通过utf8和unicode转化工具查看。
另外,说一下我们的通常表示法。utf8的16进制数表示开头加0x,unicode开头加U+。所以,帆字的utf8的16进制应该是0xE5 0xB8 0x86,而unicode的16进制表示应该是U+5E06。这个注意一下就好了,别人家写出来咱分辨不出来。
五、十六进制转换十进制方法
这节其实是我在写这篇文章的时候遇到的问题。在这里我也就不单独拿出来写了,直接在这里温故而知新吧。我们在表示十六进制的时候,采用的表示法是0x。比如我们表示0xA4,其对应的十进制数怎么算呢?首先,我们要知道16进制的权为16,这个数转化为是十进制的方法和二进制转换成十进制一个道理。 是10(A) * 16的一次方+4 * 16的0次方,最终等于164.那我们算下0xFF,是不是就等于255呢?答案是没错。
六、大端法和小端法
计算机在存储器重排列字节有两种方式:大端法和小端法,大端法就是将高位字节放到底地址处,比如0x1234, 计算机用两个字节存储,一个是高位字节0x12,一个是低位字节0x34,它的存储方式为下:
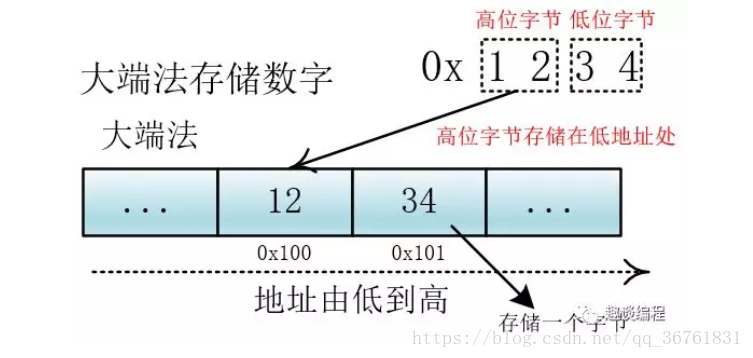
TF-32用四个字节表示,处理单元为四个字节(一次拿到四个字节进行处理),如果不分大小端的话,那么就会出现解读错误,比如我们一次要处理四个字节 12 34 56 78,这四个字节是表示0x12 34 56 78还是表示0x78 56 34 12 ,不同的解释最终表示的值不一样。
七、UTF-16
utf-16也是边长字节表示,我们可以简单看看其表示的方法,不用太细的去看,等到真碰上了再思考也不迟。
- 对于编号在U+0000到U+FFFF的字符(常用字符集),直接用两个字节表示。
- 编号在 U+10000到U+10FFFF之间的字符,需要用四个字节表示。
同样,UTF-16 也有字节的顺序问题(大小端),所以就有UTF-16BE表示大端,UTF-16LE表示小端。
八、UTF-32
utf-32是字符对应标号的证书二进制形式,四个字节,直接转化就可以了。比如帆的unicode为U+5E06,直接转化成二进制后得到:0101 1110 0000 0110
我们可以根据他们高低字节的存储位置来判断他们所代表的含义,所以在编码方式中有 UTF-32BE 和 UTF-32LE ,分别对应大端和小端,来正确地解释多个字节(这里是四个字节)的含义。
九、随便用GO玩玩
本来想用GO实现下编码互转的,但是后来发现GO原声只支持UTF-8编码,如果想用GB2312等编码还得去get包,我尝试了下但是timeout了。哎,临近国庆,很多东西都用不了啦。以后有需要再弄吧。
package main
import (
"fmt"
"unicode/utf8"
)
func main(){
b := []byte("Hello, 帆")
for len(b) >0{
r,size := utf8.DecodeLastRune(b)
fmt.Printf("%c %v\n",r,size)
b = b[:len(b)-size]
}
c := []byte("帆")
fmt.Println(c)
}
打印结果:
帆 3
1
, 1
o 1
l 1
l 1
e 1
H 1
[229 184 134]
我们可以看到,utf8的中文在GO中是占3个字符的。而且帆的utf8的16进制数E5 B8 86转换成十进制就是[229 184 134]。
参考文章: