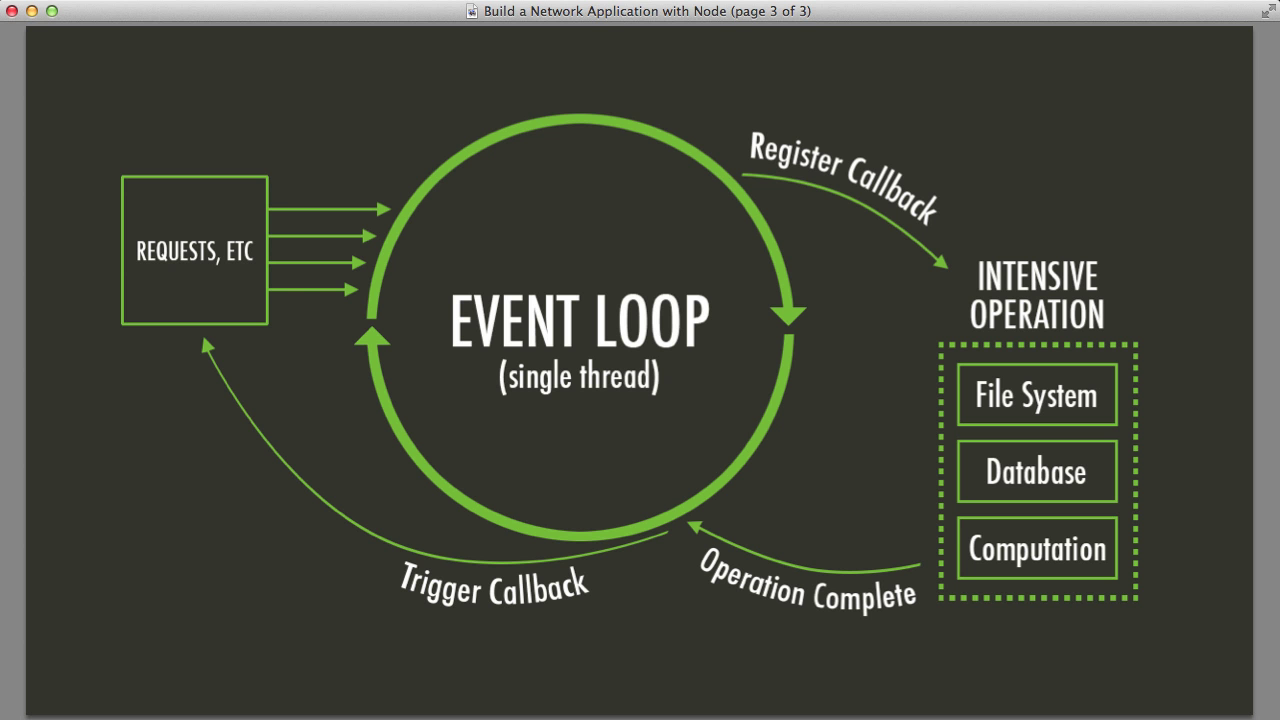
这两个星期一直在想着写一篇关于javascript中event Loop的文章。自从写完上一篇《Javascript捕捉(capturing)与冒泡(bubbling)的区别》之后,我抛出了一个问题。当时的我对event loop的概念还很模糊,只是觉得这个问题隐隐约约跟它有关系。我当然不能放下这个问题太久,太久了就会忘记自己原先的初衷了。所以,在看了很多关于event loop的文章和视频以后我打算将这篇文章写出来。在文章的最后,我将列举出我所翻阅的所有资料,而且我很建议大家看一看。
想要了解event loop的概念,首先就要知道几个有关的概念。
- 什么叫做栈
栈(stack),是计算机内存存储的一种方式。数据进入栈叫做压栈,数据从栈中出来叫做出栈。栈的存储方式只支持先进后出,后进先出的原则。如果你熟悉C语言的话,你就会知道栈中的数据是静态数据,这些数据是由计算机分配的数据,不能被我们程序员进行更改。
- 什么叫做堆
堆(heap),也是计算机内存存储的一种方式。数据根据所属的某种key分散存储在内存单元。同样你如果熟悉C语言的话,你就会知道堆中的数据是动态数据,是由操作者们单独创建出来的存储单元。
- 什么叫做队列
队列(queue),他是一种解决问题的方法。我们人为的规定队列中的数据具有先进先出,后进后出的规则。也就是说如果你想出队你就必须等你前面的所有数据全部出队以后你才可以出队。
我相信有了以上的几种知识,你就能够明白我接下来要解释的长篇大论了。我们知道多个事情并发的时候就会出现你忙不过来的情况,如果你忙不过来那么就得让所有后面的事情等待你先解决手头的事情。这样就会出现后面的事务堆积得不到解决,那么我们怎么解决这个问题呢?javascript采用的并发模型是基于“事件循环”的。那什么叫做事件循环呢?下面我就一点一点展开。
首先声明的是,javascript是单线程的。他不可能有多线程的性质,而只是在模仿多线程的样子让我们感觉像多线程一样。
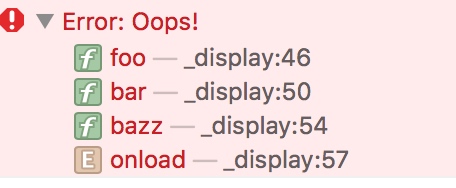
从上图,我们可以看到这段代码展示的形式就是栈的表示方法。最先运行的代码最先压进栈,我们可以看到onload其实就是代码的main函数,然后依次压栈bazz,bar,foo,而在foo中抛出一个错误停止了程序的运行。
在javascript中我们运行代码的时候,如果执行的时间很长,那么我们在这段时间内是做不了别的事情的。这就是单线程的弊端。我们可以运行个例子进行测试。
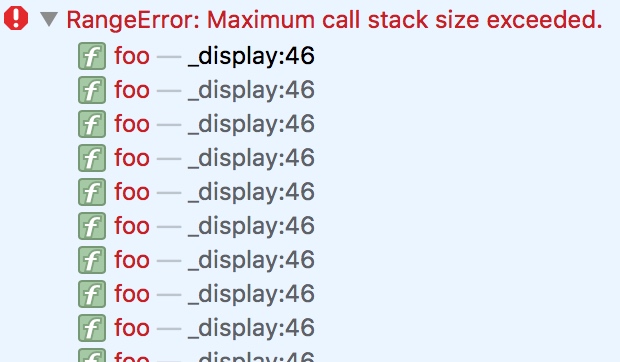
上面的程序,我们进行了递归调用,并且没有做异常处理。那么运行的时候会无限的调用foo函数直到碰触到内存中的栈最大值,这个时候js会抛出系统异常并终止程序。
在这里我有个好奇点,栈到底有多大呢?当然,我不能具体量化到栈可以存储多少个字节,但是我可以通过循环的次数大体判断一下。
这段代码在不同的浏览器中会有不同的结果,大体结果如下:
Internet Explorer
- IE6: 1130
- IE7: 2553
- IE8: 1475
- IE9: 20678
- IE10: 20677
- IE11:54375
- edge : 16615
Mozilla Firefox
- 3.6: 3000
- 4.0: 9015
- 5.0: 9015
- 6.0: 9015
- 7.0: 65533
- 8b3: 63485
- 17: 50762
- 18: 52596
- 19: 52458
- 42: 281810
- 49: 8921
Google Chrome
- 14: 26177
- 15: 26168
- 16: 26166
- 25: 25090
- 28: 26000
- 47: 20878
- 51: 41753
- 56: 20922
Safari
- 4: 52426
- 5: 65534
- 9: 63444
- 10: 73399
Opera
- 10.10: 9999
- 10.62: 32631
- 11: 32631
- 12: 35990
不过以上的数据并不能说明什么,因为当你再用同样的版本浏览器再次运行脚本的时候会发现得出的结果和上次并不太一样。何况这也取决你所处的软件环境和内存运行情况。所以说,这些结果也就是玩玩而已并没有什么实际意义。
接下来,让我们看看js在运行程序的时候是如何在栈中存储的吧。

我们看到js在启动的时候先将main()函数压入栈底,然后运行到printSquare()时将其压入栈中,紧接着将square和multiply接连压栈。这样就构造出了完整的printSquare()函数运行栈,紧接着程序将按照出栈的顺序开始执行,直到栈空为止。下面让我们接着来看下远程调用数据时的情况。

这个效果和上一个例子的运行效果是一样的,但是我们注意到每个远程调用都是需要一段时间等待的,如果一个连接网络用时超长那么给我们的感觉就如同卡死一样,我们既不能操作别的动作,浏览器也不能处理诸如渲染页面之类的操作。这一问题是非常严重的,原因所在就是js是单线程的,浏览器只能完成一个任务之后再去执行下一个任务。
那么我们需要一个解决办法,这个办法就是你常用的异步回调,更准确的说就是回调函数。我们运行的时候将其运行过程保存起来,在将来的某个时间点再运行。请注意在这里所说的某个时间点的概念,请务必带着“哪个时间点?”的问题往下看。虽然我可以直接告诉你答案~
我期望你能够运行一下并在浏览器中的控制台查看结果。
setTimeout函数将方法体保存在了队列中以让他在将来的5秒后运行。这个时候队列的概念出来了。那么问题又来了,从代码直观上来看,这样的运行结果并不稀奇,因为我让方法体5秒后执行,可不就是先执行下面的代码了么?我们再来看个例子,请你对上面的代码修改5秒为0秒,试下看看结果变没有变。
答案是没有变,虽然设置为了0秒。但他并不就等同于立即执行,而是某种东西将其放到了队列中,当别的步骤都走完了才能开始运行队列中的代码。请注意这里所述的“某种东西”并不是javascript,而是浏览器,更准确的说是浏览器底层的C++。我们可以查看window.setTimeout,setTimeout是底层WEB API提供的接口,他是我们在使用javascript编写web代码时由底层进行的。所以setTimeout并不是javascript的特性,而是浏览器。再进一步说,我们在做异步的时候是浏览器在帮助我们将方法体塞进队列,然后在未来的某个时间再从队列出来并执行的,从而给了我们一种异步的感觉。javascript是单线程的这句话,这里淋漓尽致的体现出来了吧。还有,网上各种文章标题什么的js的setTimeout其实都是bullshit。
接下来,让我们真正带着event loop的概念看一看是如何进行的。
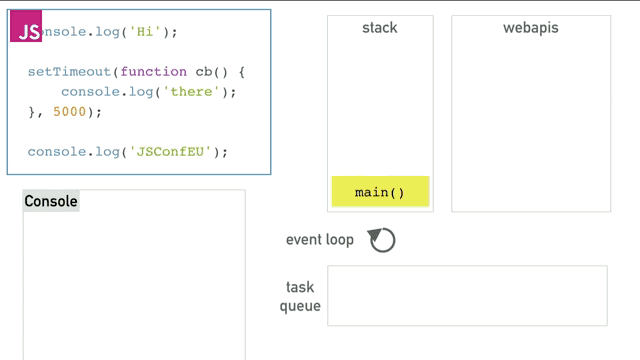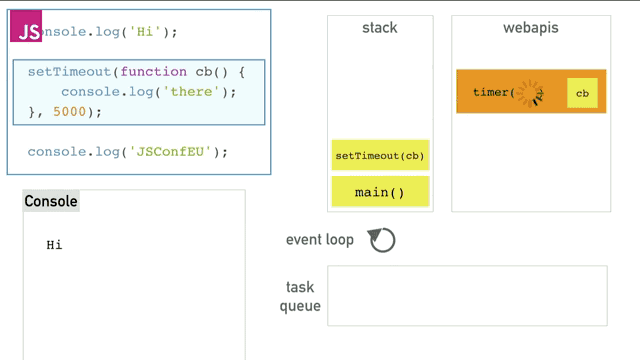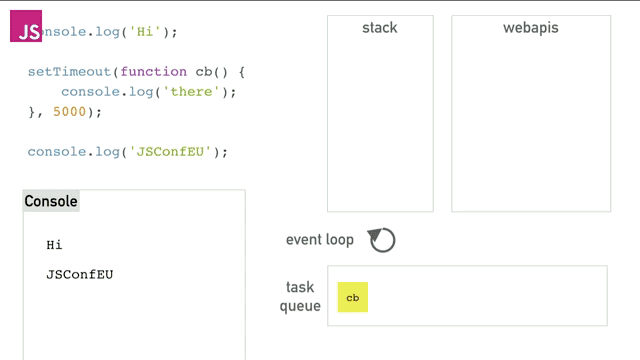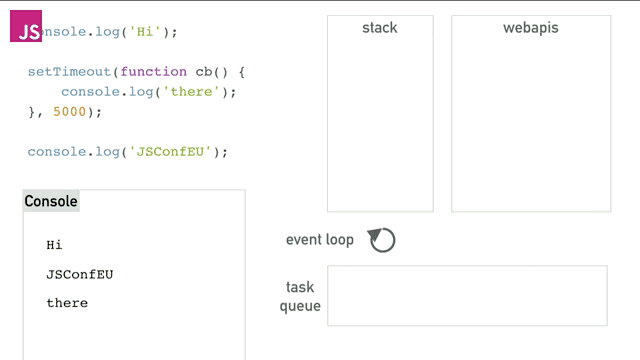
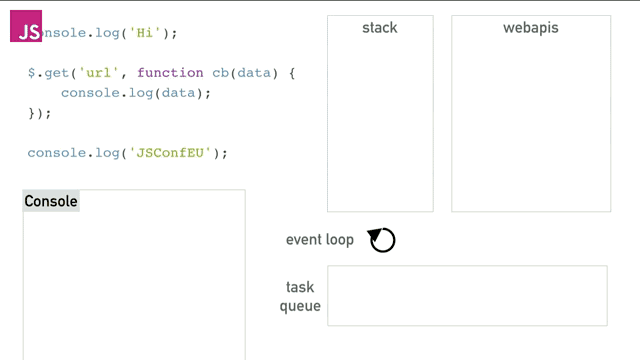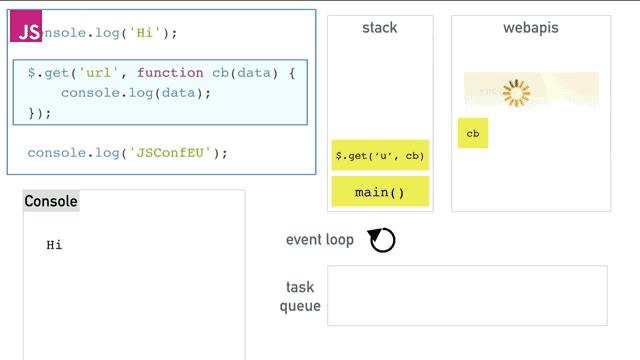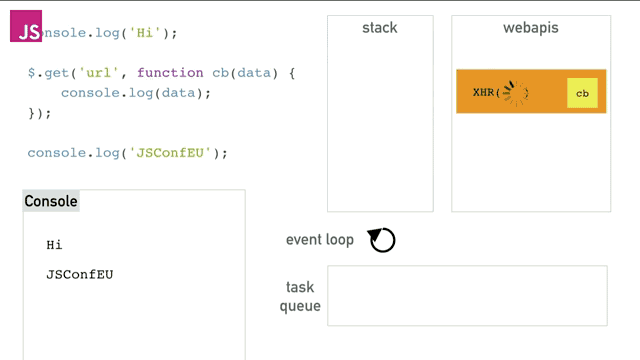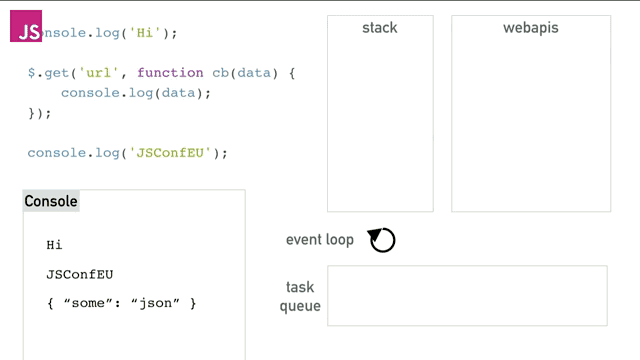
这个程序中直到webapis存储着timer之前的逻辑我不讲了(前面已经说的足够了),之后timer运行5秒以后将cb()函数塞进队列中,event loop会一直干两件事,一是检查栈中是否为空,二是检查队列是否为空。如果队列中不空就将最先执行的cb函数在栈为空的时候压栈并执行。最终得到的效果就如同异步一样,完美的完成了异步操作。
接下来让我们看看Ajax的情况吧,其实和之前的例子没有什么两样的。
如果很多的异步回调(几乎)同时触发,那么是什么情况呢?
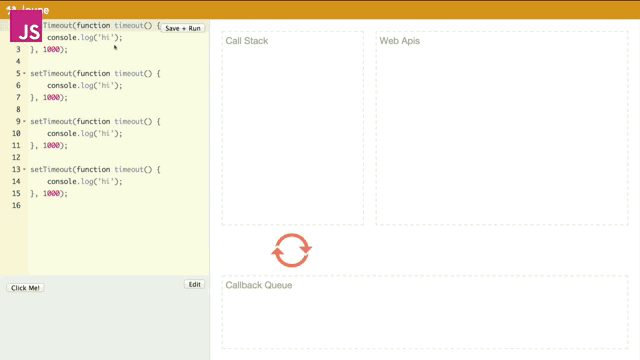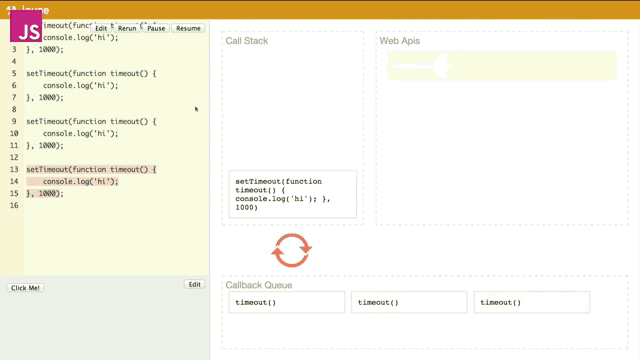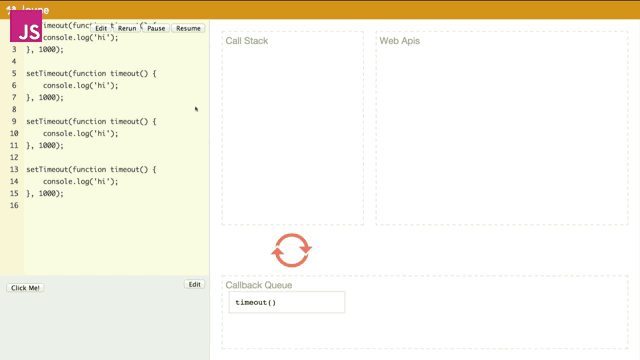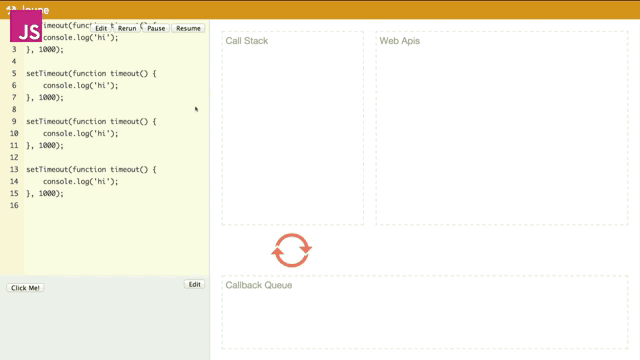
就像刚才我所提到event loop所干的两件事,它一直在监察着栈和队列。当第一个timeout进入队列要出队列的时候,event loop发现栈中还在运行代码,所以就先不让其出队列而是等到栈中为空时才出队列,之后进来的timeout函数都要被event loop告知栈为空时才可以一个一个进行出队列并执行。
如果你想了解更多的话,我强烈建议你点击下边第三个引用连接,这个连接里面的内容是一个js运行时的模拟器,你可以自己写程序,他可以直观的帮助你了解你写的程序在系统中是如何执行的。
- https://www.youtube.com/watch?v=8aGhZQkoFbQ
- https://2014.jsconf.eu/speakers/philip-roberts-what-the-heck-is-the-event-loop-anyway.html
- 相当推荐的工具,由于连接较长影响了美观,所以做成了超链接
- https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/EventLoop
- https://developer.mozilla.org/en-US/docs/Web/API/Window/postMessage
- https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/RangeError