
在操作mysql的时候,为了理解mysql的特性我们往往需要构造出一张承载很大数据量的数据表。那么如何创建出大数据量的表呢?
首先,我们要在自己的脑中先设想出能够满足这个需求的几个实现方案:
- 通过你所掌握的语言编写脚本实现
- 在数据库中直接通过脚本实现
第一种方案实现起来比较简单,对我来说php是我的主语言,我用php去实现这个需求的业务逻辑很简单。但是,在实际的操作中就会发现光光写好一段能够满足此需求的逻辑还远远不够,我们还需要考虑运行程序机器的内存限制以及超时时间等。与直接通过数据库脚本实现来说,性能和时间都不是很有优势。
第二种方案实现起来稍微复杂且需要一点点学习成本,首先是需要掌握最基本的数据库操作知识,其次还要通过编写mysql存储过程的标准格式。但是,运行起来的速度以及方便程度还有性能都远远比第一种方案来的效率。
首先,我们需要将数据表结构建立起来。
CREATE TABLE millionData (
id INT NOT NULL,
email VARCHAR(64) NOT NULL,
name VARCHAR(32) NOT NULL,
password VARCHAR(32) NOT NULL,
phone VARCHAR(13),
birth DATE,
sex INT(1),
avatar BLOB,
address VARCHAR(64),
regtime DATETIME,
lastip VARCHAR(15),
modifytime TIMESTAMP NOT NULL,
PRIMARY KEY (id)
)ENGINE = MyISAM ROW_FORMAT = DEFAULT
partition BY RANGE (id) (
partition p0 VALUES LESS THAN (100000),
partition p1 VALUES LESS THAN (500000),
partition p2 VALUES LESS THAN (1000000),
partition p3 VALUES LESS THAN (1500000),
partition p4 VALUES LESS THAN (2000000),
Partition p5 VALUES LESS THAN MAXVALUE
);
我们规定首先选择引擎为MyISAM,因为MyISAM的插入速度要比INNODB的插入速度快出10%。如果需要INNODB引擎的表,就在数据插入完成以后再对表进行此操作即可:
alter table millionData engine=innodb
虽说,这条语句在更改的时候也需要时间。但是,相对于直接用innodb引擎的表进行插入来说还是要快很多的。接下来,我们就要对此表进行数据的插入了。
CREATE DEFINER=`root`@`localhost` PROCEDURE `BatchInsertMillionData`(IN `start` int, IN loop_time int)
DETERMINISTIC
BEGIN
DECLARE Var INT;
DECLARE ID INT;
SET Var = 0;
SET ID= start;
WHILE Var < loop_time
DO
insert into millionData(ID,email,name,password,phone,birth,sex,avatar,address,regtime,lastip,modifytime)
values(ID,CONCAT(ID,'@sina.com'),CONCAT('name_',rand(ID)*10000 mod 200),123456,13800000000,adddate('1995-01-01',(rand(ID)*36520) mod 3652),Var%2,'http:///it/u=2267714161,58787848&fm=52&gp=0.jpg','北京市海淀区',adddate('1995-01-01',(rand(ID)*36520) mod 3652),'8.8.8.8',adddate('1995-01-01',(rand(ID)*36520) mod 3652));
SET Var = Var + 1;
SET ID= ID + 1;
END WHILE;
END
通过阅读上面的代码,我们可以发现。BatchInsertMillionData有两个输入参数,一个是起始id,一个是要插入的数据量。代码是通过这两个输入的值做while循环,一条一条insert数据插入到数据库当中的。让我们来看看实际应用的耗时吧。
mysql>call BatchInsertMillionData(1,1000000);
Query OK, 1 row affected (1 min 21.30 sec)
让我们多做一步
mysql> truncate table millionData;
Query OK, 0 rows affected (0.02 sec)
mysql> alter table millionData disable keys;
Query OK, 0 rows affected (0.01 sec)
mysql> call BatchInsertMillionData(1,1000000);
Query OK, 1 row affected (1 min 23.05 sec)
mysql> alter table millionData enable keys;
Query OK, 0 rows affected (0.00 sec)
从上面的两个运行方法来看,第二种在运行存储过程之前对myisam表进行了关闭索引的操作。然而完成的时间并没有提高反而慢了1秒多。为什么我会增加这个步骤呢?这是因为有人说这步骤可以实现打开/关闭myisam表非唯一索引的更新。然而,我并没有对此表任何字段添加任何索引。所以,以最后的完成时间来看。关闭key的操作并没有对我的插入起到什么效果。那好,我们就对这张表增加几个非唯一索引来试试。
mysql> truncate table millionData;
Query OK, 0 rows affected (0.01 sec)
mysql> alter table millionData add key name(name);
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> alter table millionData add key phone(phone);
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> alter table millionData add key phoneAndName(phone,name);
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> show create table millionData;
(中间的制表符省略)
| Table | Create Table
(中间的制表符省略)
| millionData | CREATE TABLE `millionData` (
`id` int(11) NOT NULL,
`email` varchar(64) COLLATE utf8_bin NOT NULL,
`name` varchar(32) COLLATE utf8_bin NOT NULL,
`password` varchar(32) COLLATE utf8_bin NOT NULL,
`phone` varchar(13) COLLATE utf8_bin DEFAULT NULL,
`birth` date DEFAULT NULL,
`sex` int(1) DEFAULT NULL,
`avatar` blob,
`address` varchar(64) COLLATE utf8_bin DEFAULT NULL,
`regtime` datetime DEFAULT NULL,
`lastip` varchar(15) COLLATE utf8_bin DEFAULT NULL,
`modifytime` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
KEY `name` (`name`),
KEY `phone` (`phone`),
KEY `phoneAndName` (`phone`,`name`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8 COLLATE=utf8_bin
/*!50100 PARTITION BY RANGE (id)
(PARTITION p0 VALUES LESS THAN (100000) ENGINE = MyISAM,
PARTITION p1 VALUES LESS THAN (500000) ENGINE = MyISAM,
PARTITION p2 VALUES LESS THAN (1000000) ENGINE = MyISAM,
PARTITION p3 VALUES LESS THAN (1500000) ENGINE = MyISAM,
PARTITION p4 VALUES LESS THAN (2000000) ENGINE = MyISAM,
PARTITION p5 VALUES LESS THAN MAXVALUE ENGINE = MyISAM) */ |
(中间的制表符省略)
1 row in set (0.00 sec)
接下来我们运行两种方法的插入。
mysql> call BatchInsertMillionData(1,1000000);
Query OK, 1 row affected (2 min 1.12 sec)
mysql> truncate table millionData;
Query OK, 0 rows affected (0.01 sec)
mysql> alter table millionData disable keys;
Query OK, 0 rows affected (0.00 sec)
mysql> call BatchInsertMillionData(1,1000000);
Query OK, 1 row affected (1 min 27.24 sec)
alter table millionData enable keys;
Query OK, 0 rows affected (7.87 sec)
可以看到,我们对此表增加了3个索引(一张表建议最好不要添加多于6个索引)。两个普通索引和一个关联索引。没有关闭非唯一索引的插入时间要比关闭非唯一索引的插入时间慢了半分钟,虽然最后开开了索引也只是在用时8秒。所以说,如果你的表建立的时候就建立了索引,在导入大批量数据之前,一定要先尝试着关闭这些索引,这一个步骤会让你省去很多的等待时间。
上面我们插入的是一百万数据而已,那么接下来我们尝试插入一亿条数据试试。我们建立一张表,同样用的也是之前的建表语句,只是表的名称改成了billionData。讲个题外话,你是不是经常搞不清million和billion谁大以及各代表的数字呢?我告诉你们一个好方法,你只要记住b比m大,而b是3个3个0,m是2个3个0。因为,外国人记录数字都习惯用3个0位一个段。所以,million代表1,000,000,billion代表1,000,000,000。
如果我们还是用上面的那个存储过程的话,很悲催,最后会出现query超时或者丢失的提示,而进程还没等数据插入完成就早早停止住了。这是因为mysql在做数据插入的时候是有一个循环体在不断的向mysql中注入信息的,如果要插入的数据时时刻刻都在往这个循环内插入数据,然而写入磁盘的数据量是有上限的,这样一来数据远远超过了消费数据的能力,mysql就会报出这样的错误来。那么问题来了,我们需要怎么修改存储过程才能满足这个需求呢?
CREATE DEFINER=`root`@`localhost` PROCEDURE `BatchInsertBillionData2`(IN start int(11), IN loop_time int(11))
BEGIN
DECLARE times INT;
DECLARE ID INT;
DECLARE j INT;
DECLARE count INT;
SET ID = start;
SET times = loop_time/1000;
SET count = 0;
SET @exedata = "";
WHILE count < times DO
SET j = 0;
WHILE j < 1000 DO
SET @exedata = concat(@exedata,",('",ID,"','",CONCAT(ID,'@sina.com'),"','",CONCAT('name_',rand(ID)*10000 mod 200),"','123456','13800000000','",adddate('1995-01-01',(rand(ID)*36520) mod 3652),"','",ID%2,"','http://it/u=2267714161,58787848&fm=52&gp=0.jpg','北京市海淀区','",adddate('1995-01-01',(rand(ID)*36520) mod 3652),"','8.8.8.8','",adddate('1995-01-01',(rand(ID)*36520) mod 3652),"')");
SET j = j+1;
SET ID = ID + 1;
end while;
SET @exedata = SUBSTRING(@exedata,2);
SET @exesql = concat("insert into billionData(ID,email,name,password,phone,birth,sex,avatar,address,regtime,lastip,modifytime) values ",@exedata);
prepare stmt from @exesql;
execute stmt;
DEALLOCATE prepare stmt;
SET @exedata = "";
SET count = count +1 ;
end while;
END
以上就是对存储过程的修改,大概意思就是判断要插入的数据量除以1000,所得到的数字就是最外层循环的循环次数,内层循环再做1000此循环,循环体就是在每次循环中将sql组成类似insert into billionData(…) values (…),…,(…)的形式然后再通过prepare和execute进行分批量的插入。这样一是将1000次的请求汇成一个请求然后异步的去插入数据库,然后马上再进行下一个1000次的组装和插入。这样就不会发生丢失query连接的报错了。
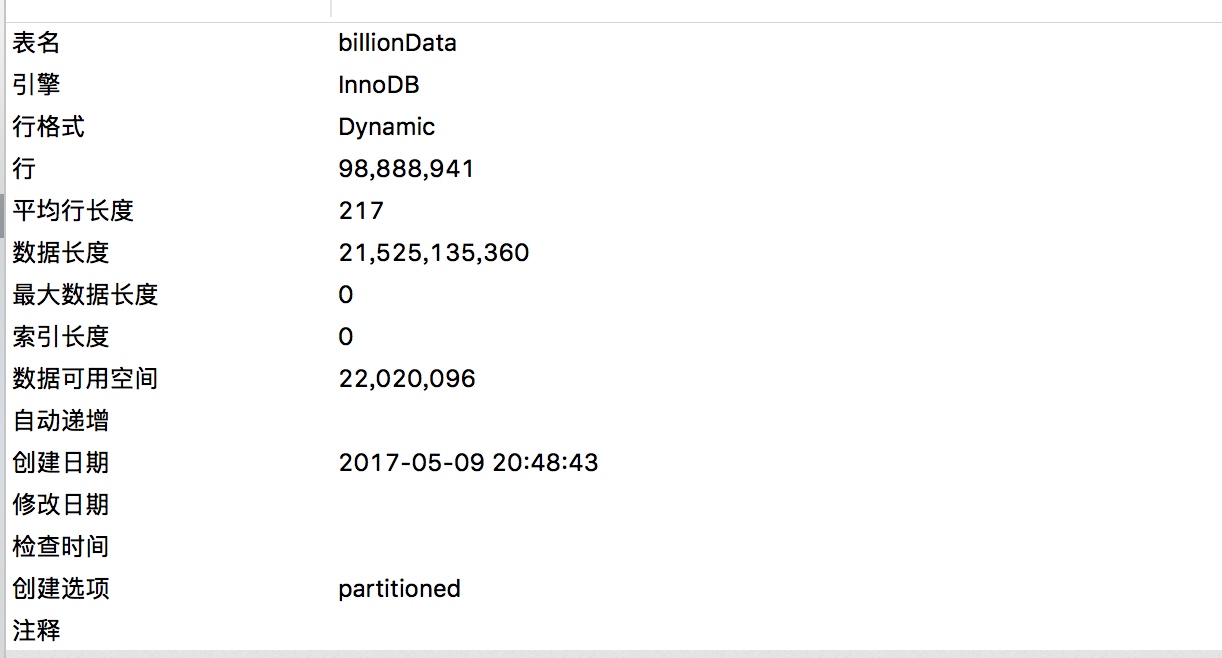
想说一下用这个方法插入了一亿条数据的耗时吧。这段代码大约耗时2个多小时,总数据量在17G左右,每秒20000条插入到数据表中。在没有任何索引的情况下,将此表引擎改成innodb花了12分钟左右:
mysql> alter table billionData engine=innodb;
Query OK, 0 rows affected (11 min 51.20 sec)
以下写于2017-05-10
首先,让我插个题外话。今天凌晨,2017年欧冠半决赛尤文图斯战胜了摩纳哥。时隔两年尤文图斯又站上了欧冠的巅峰,接下来就要看明日凌晨皇马和马竞谁能赢了,不过皇马已经在前半回合3比0领先马竞了,不出意外皇马不会被马竞翻盘的,毕竟现在C罗如日中天屌的一逼。回想2015年10月我也是曾经在卡尔德隆球场看过皇马对马竞比赛的男人。
好了,扯回来吧。之前的方式还不是最高效的。后来,了解到还有一种大法就是Load data。这个方法简直高效的要命,时间占用比例是之前的约5%,提升了95%的速度呢。为了进行测试我将昨日插入的一百万数据导出成txt,让我们先看一下mysql导出这个文件花了多长时间。
接着,让我们来用load data的方法尝试插入数据库吧。
mysql> truncate table millionData;
Query OK, 0 rows affected (0.09 sec)
load data local infile '/Users/yifanzhang/Downloads/millionData.txt' into table millionData;
ERROR 1148 (42000): The used command is not allowed with this MySQL version
上来就遇到了error的报错。通过报错我们知道是因为这个方法是不被当前的数据库版本所支持的。经过查询手册得知:
LOCAL works only if your server and your client both have been configured to permit it. For example, if mysqld was started with –local-infile=0, LOCAL does not work. See Section 6.1.6, “Security Issues with LOAD DATA LOCAL”.
local关键字只有服务器端和客户端都设置为允许的情况下才可以使用。默认情况下mysqld是以–local-infile=0开始启动的,所以local不能够工作。
所以说有两种方式可以将local功能打开。一种是在启动mysql客户端时带上允许local的参数,一种是配置在my.cnf中的,允许mysql一直保持local的开启。显然,我是在做测试,毕竟这个功能不会一直用到,所以我采用的就是第一种方法。那么我们先退出mysql,然后重新启动mysql客户端。
mysql --local-infile -uroot test
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 35
Server version: 5.7.10 Homebrew
Copyright (c) 2000, 2015, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> load data local infile '/Users/yifanzhang/Downloads/millionData.txt' into table millionData;
Query OK, 1000000 rows affected, 65535 warnings (5.88 sec)
Records: 1000000 Deleted: 0 Skipped: 0 Warnings: 12000000
mysql> truncate table millionData;
Query OK, 0 rows affected (0.20 sec)
mysql> alter table millionData add index name(name);
Query OK, 0 rows affected (0.03 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> alter table millionData add index phone(phone);
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> alter table millionData add index phoneAndName(phone,name);
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> load data local infile '/Users/yifanzhang/Downloads/millionData.txt' into table millionData;
Query OK, 1000000 rows affected, 65535 warnings (11.70 sec)
Records: 1000000 Deleted: 0 Skipped: 0 Warnings: 12000000
通过测试,我们可以看到用load data的方式插入数据,在数据表没有索引以及有索引的情况下,性能都要比之前的每一种方法快很多。只是,这种方法你需要导入的数据文本以及打开相关配置。在什么时候使用哪种情况,完全取决于你所处的环境之下。
PS:拥有一千万数据量的millionData.txt总大小为146.2MB,在数据库中包括三个索引的容量为41MB。